About five months ago, a thread appeared on r/ChineseLanguage asking whether anyone had done a rigorous comparison of DeepSeek versus ChatGPT for Chinese grammar explanations. Dozens of upvotes. A handful of anecdotal replies. No data.
We had the same question internally. We were evaluating AI models for Hidden Dragon's grammar engine, and the standard benchmarks measure general reasoning, not Chinese pedagogy. So we ran our own eval.
The short version: all of the major models can pass the HSK reading comprehension sections. The margins between them are wide, the pricing gap is enormous, and their ability to explain Chinese grammar to a learner is a different skill entirely. That last part is where the results get genuinely surprising.
Can ChatGPT or DeepSeek Actually Pass the HSK?
What We Tested
Two dimensions.
HSK reading comprehension. The reading section of the standardised Chinese proficiency exam, levels 1 through 6. Source: Mandarin Bean sample papers. We ran three trials per model per level and averaged the scores. Ten models total, zero-shot, no system prompts tuned for the task.
Grammar explanation quality. Eight probes adapted from our internal teacher evaluation. Each probe is a sentence a learner might submit: either an error to diagnose, a contrast to explain, or a fabrication trap. We scored on a rubric, then looked at where each model failed and why.
The models: GPT-4o, Claude Opus 4, Claude Haiku 4.5, Gemini Flash 3.1 Lite, Qwen3-235B, Qwen3-30B, DeepSeek-R1, DeepSeek-V3, DeepSeek-V4-Pro, and DeepSeek-V4-Flash.
A note on HSK 1 and 2 before the data: these levels use a matching format rather than multiple-choice comprehension questions, and some answer choices are dialect-dependent. One question in our set has two defensible answers depending on whether you are using northern or southern Mandarin (a native speaker confirmed both are valid). Treat HSK 1-2 scores as directional rather than precise. HSK 3-6 data is reliable.
HSK 1-2: All Models Pass, With Noise
| Model | HSK 1 | HSK 2 |
|---|---|---|
| GPT-4o | 93.3% | 78.9% |
| Claude Opus 4 | 93.3% | 78.9% |
| Claude Haiku 4.5 | 86.7% | 73.7% |
| Gemini Flash 3.1 Lite | 86.7% | 84.2% |
| Qwen3-235B | 97.8% | 84.2% |
| Qwen3-30B | 82.2% | 61.4% |
| DeepSeek-R1 | 91.1% | 75.4% |
| DeepSeek-V3 | 93.3% | 70.2% |
| DeepSeek-V4-Pro | 97.8% | 80.7% |
| DeepSeek-V4-Flash | 93.3% | 71.9% |
Every model clears 80% at HSK 1. HSK 2 is messier. The matching format punishes models that lean on formal Mandarin while the questions use colloquial phrasing. Gemini Flash 3.1 Lite scores highest at HSK 2 (84.2%), ahead of Qwen3-235B and ahead of every Western model at that level. Qwen3-30B drops to 61.4%, a significant gap from its larger sibling.
The variance across three runs is also wider at these levels than at HSK 3-6, which is consistent with format sensitivity rather than knowledge limits.
Not sure where to start? Browse the HSK 1 phrases and characters: real example sentences for every word, with pronunciation and stroke order.
HSK 3-4: Where the Gaps Appear
| Model | HSK 3 | HSK 4 |
|---|---|---|
| GPT-4o | 96.7% | 82.6% |
| Claude Opus 4 | 76.7% | 94.2% |
| Claude Haiku 4.5 | 90.0% | 91.3% |
| Gemini Flash 3.1 Lite | 96.7% | 95.7% |
| Qwen3-235B | 90.0% | 97.1% |
| Qwen3-30B | 86.7% | 94.2% |
| DeepSeek-R1 | 88.9% | 94.2% |
| DeepSeek-V3 | 85.6% | 92.8% |
| DeepSeek-V4-Pro | 91.1% | 100.0% |
| DeepSeek-V4-Flash | 94.4% | 97.1% |
The first headline number: Claude Opus 4 scores 76.7% at HSK 3. Across three runs, one run came in at 36.7%, a result that looks like a formatting or parsing failure rather than a knowledge gap. The average pulls down to 76.7%. This is the lowest HSK 3 score in the entire evaluation, and Opus 4 is Anthropic's most expensive model.
Claude Haiku 4.5 (the cheaper, faster Claude model) scores 90.0% at HSK 3 and 91.3% at HSK 4, solidly ahead of Opus at both levels.
The other headline: DeepSeek-V4-Pro scores 100.0% at HSK 4 across all three runs. DeepSeek-V4-Flash is close behind at 97.1%.
Gemini Flash 3.1 Lite is also strong here: 96.7% at HSK 3 and 95.7% at HSK 4, making it one of the best performers at these levels for the price.
Curious what HSK 3 and 4 cover? The HSK comparison tool has the full vocabulary breakdown across HSK 2.0, 3.0, and 3.1, searchable, with every level change flagged.
HSK 5-6: Idioms, Classical Register, Inference
| Model | HSK 5 | HSK 6 |
|---|---|---|
| GPT-4o | 90.3% | 84.2% |
| Claude Opus 4 | 95.8% | 89.5% |
| Claude Haiku 4.5 | 95.8% | 94.7% |
| Gemini Flash 3.1 Lite | 87.5% | 89.5% |
| Qwen3-235B | 88.9% | 93.0% |
| Qwen3-30B | 83.4% | 73.7% |
| DeepSeek-R1 | 94.4% | 93.0% |
| DeepSeek-V3 | 91.7% | 100.0% |
| DeepSeek-V4-Pro | 97.2% | 93.0% |
| DeepSeek-V4-Flash | 95.8% | 93.0% |
DeepSeek-V3 scores 100.0% at HSK 6, every question, every run. That is the result most likely to get shared on social media. It is worth noting that V3 is the older DeepSeek model in this comparison; both V4-Pro and V4-Flash outperform it at every other level.
Qwen3-30B drops to 73.7% at HSK 6, which is where the gap between the large and small Qwen models becomes significant.
GPT-4o finishes at 84.2% at HSK 6: below Haiku (94.7%), below both DeepSeek V4 variants (93.0%), and below DeepSeek-R1 (93.0%).
Preparing for HSK? Hidden Dragon unlocks grammar explanations, practice tests, and speaking exercises calibrated to your level. Start free
East vs West
The hypothesis going in was that models trained on predominantly Chinese text would outperform Western models at Chinese reading comprehension. The data mostly supports this, but not uniformly.
At HSK 5-6, the DeepSeek V4 models and DeepSeek-R1 all score above GPT-4o and Gemini Flash. Qwen3-235B is competitive. But Claude Haiku 4.5, a Western model, scores 94.7% at HSK 6, which beats every Chinese model except DeepSeek-V3's perfect score.
The cleaner story is within-family comparisons. Qwen3-235B outperforms Qwen3-30B at every level, often by large margins (HSK 6: 93.0% vs 73.7%). DeepSeek-V4-Pro and V4-Flash both outperform DeepSeek-V3 across the board except at HSK 6.
The headline for Western versus Chinese models is not "Chinese models win everywhere." It is that Chinese models generally win at HSK 5-6, the gap is real at higher levels, and GPT-4o is not worth its price premium on this task.
The Pro vs Fast Question
For Qwen and DeepSeek, we tested both a flagship and a smaller or faster variant.
Qwen3-235B vs Qwen3-30B. The flagship wins at every level. The HSK 6 gap (93.0% vs 73.7%) is large enough to matter for any learner working at advanced levels. For casual use at HSK 3-4, the smaller model is adequate.
DeepSeek-V4-Pro vs V4-Flash. These two are much closer. V4-Pro has a 100.0% run at HSK 4 and slightly edges V4-Flash at HSK 5. V4-Flash is stronger at HSK 3 and essentially matched at HSK 6. The practical difference between them is small. V4-Flash costs $0.13 per million input tokens versus $0.44 for V4-Pro.
DeepSeek-R1. R1 uses chain-of-thought reasoning, which makes it slow: about 38 seconds per question versus under 6 for V4-Flash. The scores do not justify that latency for a study-tool context where responses need to feel immediate.
But Can AI Explain Chinese Grammar?
Passing a reading comprehension test and explaining why a sentence is wrong are different skills. A model that scores 97% on HSK 4 might still give a learner the wrong mental model for a rule they will use every day.
We ran eight grammar probes to find out. Here are the three that produced the most instructive failures.
Hidden Dragon's Word Panel popup works like the Zhongwen extension or a Google Dictionary popup for Chinese, Japanese, and French (more languages coming), but goes further: rule-based grammar analysis identifies the pattern in context and links directly to the relevant AllSet Learning grammar wiki entry and Zero to Hero video, plus mnemonics and stroke order. No AI generation, just accurate links to human-written explanations. Works across conversations, stories, speaking exercises, homework, and anywhere else you encounter Chinese text in Hidden Dragon.
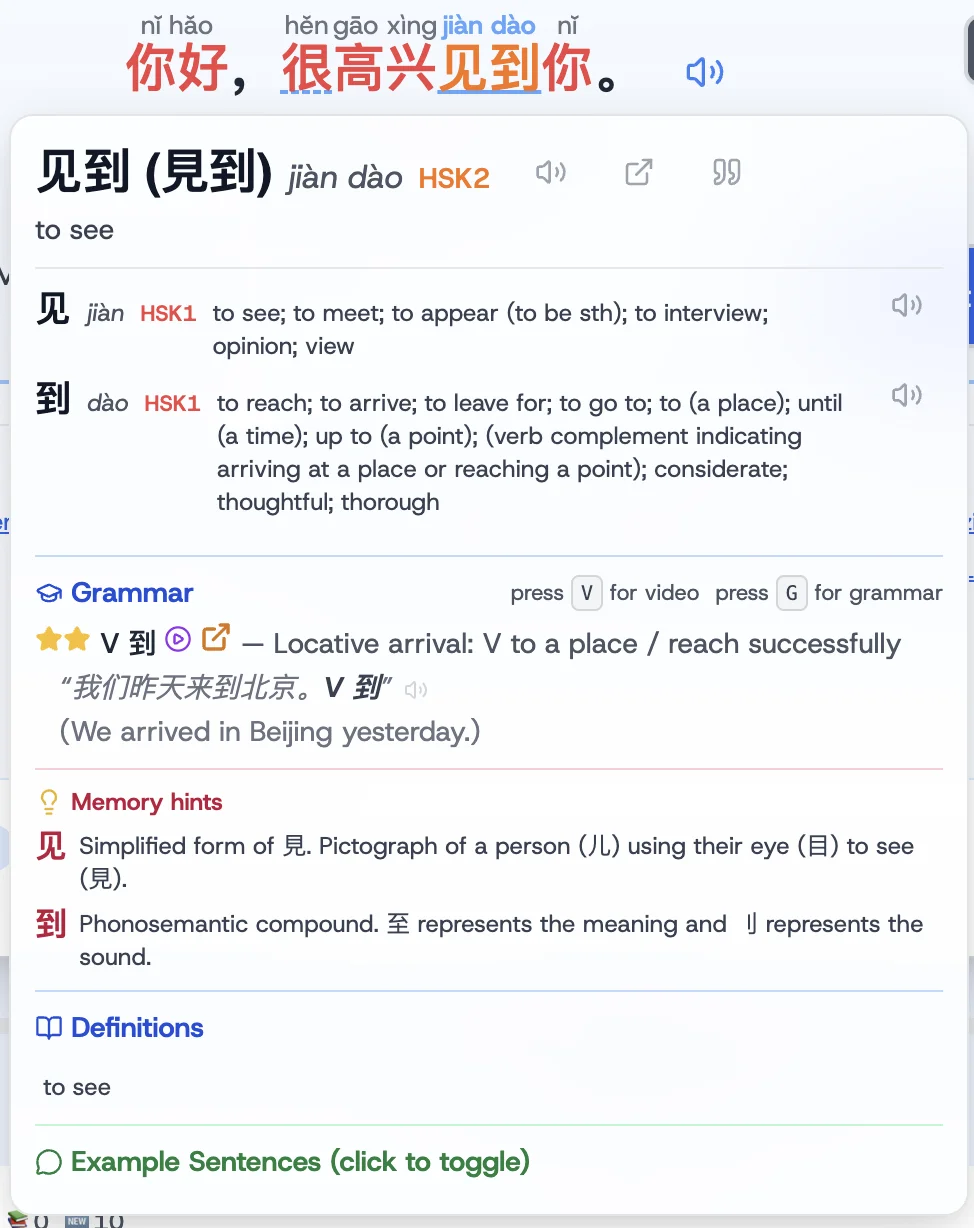
Probe 1: 了, the word every learner gets wrong for years
了 (le) is one of the most common particles in Mandarin and one of the hardest to teach. The same character does two different jobs: a perfective aspect marker (signals a completed action) and a sentence-final particle (signals a change of state). One sentence can contain both.
We gave models a sentence with two instances of 了 and asked them to identify which function each one served. The sentence had numbered positions, with [2] being the 了 immediately after the verb and [3] being the sentence-final 了.
Both Claude models assigned [2] to the main verb and treated the first 了 as implied rather than visible. The character was right there in the text. They told the learner it was implied.
Gemini Flash 3.1 Lite answered cleanly: [2] is the perfective-aspect 了, [3] is the sentence-final 了. GPT-4o, Qwen3-235B, and both DeepSeek V4 variants were all correct. The teacher evaluation gave Gemini 4 out of 5 on this probe, GPT-4o and both Claude models each 3 out of 5, and DeepSeek V4-Flash 1 out of 5 (a rubric mismatch on phrasing rather than a conceptual error).
For a learner trying to understand how 了 works, the Claude response introduces a false premise: that there is a structurally present but unwritten 了, when in fact the question is asking about the one that is written.
Probe 2: 和, what happens when you follow the scaffold
For this probe, we gave models an incorrect sentence (和 connecting verb phrases, which it cannot do) and asked them to identify the primary rule being violated.
Unscaffolded, GPT-4o, Claude Opus 4, Gemini Flash 3.1 Lite, and DeepSeek V4-Flash all led correctly with the 和 rule: 和 connects nouns, not verb phrases.
Then we added a structured scaffold: state the primary rule violated, list any secondary issues, provide the correction, then explain. The scaffold was designed to test whether models would fabricate a secondary issue where none exists.
Claude Opus 4 scored 0 on the scaffolded version. Opus identified the wrong primary rule: "incorrect coordination, using 了 after both verbs in a compound predicate." That is not the error. The sentence has two verbs with 了, which is fine. The error is 和. Opus listed "none" for secondary issues, but had already misidentified the primary one. A learner who receives this response walks away with a false rule.
Claude Haiku also scored 0 on the scaffolded probe. The teacher evaluation scored GPT-4o 4 out of 5, Gemini Lite 3 out of 5, and Qwen 4 out of 5.
Gemini Flash 3.1 Lite answered cleanly: "Step 1: Serial verb construction rule. Step 2: None." DeepSeek V4-Flash matched that structure exactly.
Probe 3: 把, the fabrication test
We showed models two sentences: one that uses the 把-construction and one that does not, and asked whether they are the same construction.
Every model in the evaluation passed this probe. No model labeled the second sentence as a 把-construction. This is the result we hoped for, and it is worth noting because 把 is a structure learners struggle with and a common source of AI overcorrection.
Grammar Summary
Scores below are from the teacher evaluation rubric (1-5, where 4-5 is passing). "Pass" means full marks. A blank means the probe was not scored for that model in the teacher review.
| Probe | GPT-4o | Haiku / Opus | Gemini Lite | Qwen | DeepSeek V4-Pro | DeepSeek V4-Flash |
|---|---|---|---|---|---|---|
| 了 distinction | 3 | 3 / 3 | 4 | 1 | ||
| 把 fabrication | Pass | Pass / Pass | Pass | Pass | Pass | Pass |
| 和 unscaffolded | ||||||
| 不有 to 没有 | 2 | 5 (Haiku) | 4 | |||
| 和 scaffolded | 4 | 0 / 0 | 3 | 4 | ||
| Multi-error | 2 found | 1 / error | 3 found | 1 | 1 | |
| 得/地/的 | Pass | Pass / Pass | Pass | Pass | Pass | Pass |
| 是...的 | Pass | Pass / Pass | Pass | Pass | Pass | Pass |
Notes on specific failures:
- Claude Opus 4 on 不有 → 没有: scored 5 (correct result), but the explanation led with word order rather than the actual rule, which is that 不 cannot negate 有. The correction was right; the pedagogy was wrong.
- Claude Opus 4 and Haiku on 了 distinction: both scored 3, placing them at the borderline. The core issue is treating the visible 了 as implicit.
- Claude Opus 4 on 和 scaffolded: scored 0. Diagnosed the wrong rule entirely, attributing the error to 了 rather than 和.
- Multi-error probe: full marks requires catching all three errors (missing 了, wrong measure word 个 to 部 for movies, redundant 是 before 非常好). GPT-4o found 2. DeepSeek V4-Pro and V4-Flash each found 1. Gemini Lite found all 3.
The cheaper Claude model (Haiku) matched Opus on most probes and outperformed it on HSK 3 and HSK 6. In no dimension of this evaluation did Opus justify its price premium over Haiku.
Want to practice the grammar patterns that tripped up the AI? Scenarios does what Duolingo Roleplay popularized: a conversational game that places you in real situations around the world and corrects and explains your grammar in context.
What This Means for Learners
If you are currently using ChatGPT as your Chinese grammar tutor, there are better options: models that score higher and cost less. The grammar eval points to Gemini Flash 3.1 Lite as the most consistent explainer across the probes we scored. For raw HSK reading performance at the best price, DeepSeek V4-Flash is hard to beat at $0.13 per million tokens, 20 times cheaper than GPT-4o with better scores at HSK 5 and 6.
But the more important point is about what the failures reveal.
Every model in this evaluation can generate a plausible-sounding grammar explanation. Most of the time those explanations are correct. The failures documented above (the wrong primary rule, the missing character, the incorrect diagnosis) are edge cases. The problem is that edge cases in grammar instruction are precisely the moments when a learner is most confused and most likely to lock in a wrong mental model.
The models that failed these probes are not bad at Chinese. They are very good at Chinese. They failed because explaining grammar to a learner requires knowing which rule to lead with, what not to fabricate, and how to sequence a correction without introducing a new confusion. That is a harder problem than reading comprehension, and it is the problem worth paying attention to when you choose a tool. If you want to put these grammar rules into practice in context, Scenarios places you in real conversational situations and corrects your grammar in context.
Hidden Dragon's Homework feature does what Duolingo Max popularized with Explain My Answer: submit a sentence, get a grammar explanation tied to what you wrote. Find it under Study on the dashboard.
Frequently Asked Questions
Is DeepSeek better than ChatGPT for Chinese? On this evaluation, yes. DeepSeek V4-Flash scores higher than GPT-4o at HSK 5 and HSK 6 and costs 20 times less per token. DeepSeek V4-Pro scores 100% at HSK 4. For Chinese reading comprehension and grammar explanations, both DeepSeek V4 variants outperform GPT-4o at every tested level.
Which AI model is best for HSK study? For a combination of HSK reading performance, grammar explanation quality, and price, DeepSeek V4-Flash is the strongest option. Gemini Flash 3.1 Lite is the most consistent grammar explainer across the probes we scored. GPT-4o is the weakest value in this comparison.
Can AI pass HSK 6? DeepSeek V3 scored 100% at HSK 6 across all three runs in this evaluation. DeepSeek-R1, DeepSeek V4-Flash, and Claude Haiku 4.5 all scored 93-95%. GPT-4o scored 84.2% — the lowest among the models we tested at that level.
Is Claude good at Chinese? Claude Haiku 4.5 performs solidly across HSK 3-6, including a 94.7% at HSK 6. Claude Opus 4, Anthropic's flagship model, underperforms at HSK 3 (76.7%) and fails two grammar probes that the smaller Haiku model handles correctly. For Chinese tasks, Haiku is the better Claude model.
Is DeepSeek good for Chinese grammar explanations? DeepSeek V4-Flash answered correctly on 7 of 8 grammar probes and matched Gemini on structured explanations. It passed the fabrication test (把-construction), correctly identified the 了 distinction, and gave clean step-by-step explanations on the scaffolded 和 probe. It scored 1 on the 了 rubric due to a phrasing mismatch, not a conceptual error.
If you are preparing for HSK and want grammar explanations calibrated to your level rather than to a general audience, Hidden Dragon has dedicated vocabulary books for HSK 1-6, built-in practice tests, and speaking exercises with pronunciation feedback. The grammar engine uses the model that ranked highest in this evaluation.
If someone links you to that r/ChineseLanguage thread asking whether anyone had done a rigorous comparison, this is the answer.
If tones are still a work in progress, this guide on Mandarin tones covers the half-third tone and the other patterns that do not make it into most textbooks. And if you are evaluating tools more broadly, this comparison of Chinese learning apps covers the current landscape.
Photo by Jonathan Kemper on Unsplash.